Introduction to heatmaply
Tal Galili and Alan O’Callaghan
2023-07-11
Source:vignettes/heatmaply.Rmd
heatmaply.RmdAuthor: Tal Galili (Tal.Galili@gmail.com)
Introduction
A heatmap is a popular graphical method for visualizing high-dimensional data, in which a table of numbers are encoded as a grid of colored cells. The rows and columns of the matrix are ordered to highlight patterns and are often accompanied by dendrograms. Heatmaps are used in many fields for visualizing observations, correlations, missing values patterns, and more.
Interactive heatmaps allow the inspection of specific value by hovering the mouse over a cell, as well as zooming into a region of the heatmap by dragging a rectangle around the relevant area.
This work is based on ggplot2 and plotly.js engine. It produces similar heatmaps as d3heatmap, with the advantage of speed (plotly.js is able to handle larger size matrix), and the ability to zoom from the dendrogram.
heatmaply also provides an interface based around the plotly R package. This interface can be used by choosing plot_method = "plotly" instead of the default plot_method = "ggplot". This interface can provide smaller objects and faster rendering to disk in many cases and provides otherwise almost identical features.
Documentation for this package is also available as a pkgdown site: http://talgalili.github.io/heatmaply/
Installation
To install the stable version on CRAN:
install.packages('heatmaply')To install the GitHub version:
# You'll need devtools
install.packages.2 <- function (pkg) if (!require(pkg)) install.packages(pkg);
install.packages.2('remotes')
remotes::install_github("ropensci/plotly")
remotes::install_github('talgalili/heatmaply')And then you may load the package using:
Basic usage
Default
The default settings in heatmaply attempt to be both useful yet not too computationally intensive. Here is an example based on the mtcars dataset:
The data was extracted from the 1974 Motor Trend US magazine, and comprises fuel consumption and 10 aspects of automobile design and performance for 32 automobiles (1973-74 models).
library("heatmaply")
heatmaply(mtcars)Correlation heatmaps
We can use the margins parameter with correlation heatmaps. heatmaply includes the heatmaply_cor function, which is a wrapper around heatmaply with arguments optimised for use with correlation matrices. Notice how we color the branches (see dendextend::color_branches for further detail on k_row and k_col):
heatmaply_cor(
cor(mtcars),
xlab = "Features",
ylab = "Features",
k_col = 2,
k_row = 2
)We can also do a more advanced correlation heatmap where the p-value from the correlation test is mapped to point size:
r <- cor(mtcars)
## We use this function to calculate a matrix of p-values from correlation tests
## https://stackoverflow.com/a/13112337/4747043
cor.test.p <- function(x){
FUN <- function(x, y) cor.test(x, y)[["p.value"]]
z <- outer(
colnames(x),
colnames(x),
Vectorize(function(i,j) FUN(x[,i], x[,j]))
)
dimnames(z) <- list(colnames(x), colnames(x))
z
}
p <- cor.test.p(mtcars)
heatmaply_cor(
r,
node_type = "scatter",
point_size_mat = -log10(p),
point_size_name = "-log10(p-value)",
label_names = c("x", "y", "Correlation")
)Data transformation (scaling, normalize, and percentize)
The variables in mtcars includes values that reflect different types of measurement, each with its own range (and meaning) of values. In such a case, it is best to transform the data so to have all the variables have comparable values.
scale
If we would assume all variables come from some normal distribution, then scaling (i.e.: subtract the mean and divide by the standard deviation) would bring them all close to the standard normal distribution. In such a case, each value would reflect the distance from the mean in units of standard deviation. The “scale” parameter in heatmaply supports column and row scaling, and can be used as follows:
(not evaluated so to reduce vignette size)
heatmaply(
mtcars,
xlab = "Features",
ylab = "Cars",
scale = "column",
main = "Data transformation using 'scale'"
)normalize
When variables in the data comes from possibly different (and non-normal) distributions, other transformations may be in order. For example, scaling on a binary variable with many 0’s and just a few 1’s will lead to a column with a very extreme value that would cause the color legend to be very skewed by that variable, leading to a masking of the distribution of the rest of the variables.
Another possibility is to use the normalize function to brings data to the 0 to 1 scale by subtracting the minimum and dividing by the maximum of all observations. This preserves the shape of each variable’s distribution while making them easily comparable on the same “scale”. Using the function on mtcars easily reveals columns with only two (am, vs) or three (gear, cyl) variables compared with variables that have a higher resolution of possible values:
(not evaluated so to reduce vignette size)
percentize
An alternative to normalize is the percentize function. This is similar to ranking the variables, but instead of keeping the rank values, divide them by the maximal rank. This is done by using the ecdf of the variables on their own values, bringing each value to its empirical percentile. The benefit of the percentize function is that each value has a relatively clear interpretation, it is the percent of observations with that value or below it.
heatmaply(
percentize(mtcars),
xlab = "Features",
ylab = "Cars",
main = "Data transformation using 'percentize'"
)Notice that for binary variables (0 and 1), percentize will turn all 0 values to their proportion and all 1 values will remain 1. This means the transformation is not symmatric for 0 and 1. Hence, if scaling for clustering, it might be better to use rank for dealing with tie values (if no ties are present, then percentize will perform similarly to rank).
is.na10 (missing values)
Reviewing missing values can easily be done using the is.na10 function. When using it with heatmaply, it is often helpful to use a non-zero grid_gap to place gaps between cells of the heatmap. Similar to heatmaply_cor, heatmaply_na is a wrapper around heatmaply with arguments optimised for the visualisation of missingness:
heatmaply_na(
airquality[1:30, ],
showticklabels = c(TRUE, FALSE),
k_col = 3,
k_row = 3
)
# warning - using grid_color cannot handle a large matrix! For example:
# airquality[1:10, ] %>% is.na10 %>%
# heatmaply(color = c("white", "black"), grid_color = "grey",
# k_col =3, k_row = 3,
# margins = c(40, 50))
# airquality %>% is.na10 %>%
# heatmaply(color = c("grey80", "grey20"), # grid_color = "grey",
# k_col =3, k_row = 3,
# margins = c(40, 50))
# Changing color palettes
We can use colors other than the default viridis. The packages cetcolor and RColorBrewer provide a number of excellent options for continuous and discrete colour palettes. These are generally designed to be perceptually uniform, and often also colorblind-friendly.
For example, we may want to use other color palettes in order to get divergent colors for the correlations (these will, sadly, often be less useful for colorblind people). These come by default when using heatmaply_cor
(not evaluated so to reduce vignette size)
heatmaply_cor(
cor(mtcars),
k_col = 2,
k_row = 2
)Another example for using colors:
heatmaply(
percentize(mtcars),
colors = heat.colors(100)
)Or even more customized colors using scale_fill_gradient_fun:
heatmaply(
mtcars,
scale_fill_gradient_fun = ggplot2::scale_fill_gradient2(
low = "blue",
high = "red",
midpoint = 200,
limits = c(0, 500)
)
)Customized dendrograms and annotation
Various seriation options
heatmaply uses the seriation package to find an optimal ordering of rows and columns. Optimal means to optimize the Hamiltonian path length that is restricted by the dendrogram structure. This, in other words, means to rotate the branches so that the sum of distances between each adjacent leaf (label) will be minimized. This is related to a restricted version of the travelling salesman problem.
The default options is "OLO" (Optimal leaf ordering) which optimizes the above criterion (in O(n^4)). Another option is "GW" (Gruvaeus and Wainer) which aims for the same goal but uses a potentially faster heuristic. The option "mean" gives the output we would get by default from heatmap functions in other packages such as gplots::heatmap.2. The option "none" gives us the dendrograms without any rotation that is based on the data matrix.
# The default of heatmaply:
heatmaply(
percentize(mtcars)[1:10, ],
seriate = "OLO"
)(not evaluated so to reduce vignette size)
# Similar to OLO but less optimal (since it is a heuristic)
heatmaply(
percentize(mtcars)[1:10, ],
seriate = "GW"
)(not evaluated so to reduce vignette size)
# the default by gplots::heatmaply.2
heatmaply(
percentize(mtcars)[1:10, ],
seriate = "mean"
)
# the default output from hclust
heatmaply(
percentize(mtcars)[1:10, ],
seriate = "none"
)This works heavily relies on the seriation package (their vignette is well worth the read), and also lightly on the dendextend package (see vignette )
Customized dendrograms using dendextend
A user can supply their own dendrograms for the rows/columns of the heatmaply using the Rowv and the Colv parameters:
x <- as.matrix(datasets::mtcars)
# now let's spice up the dendrograms a bit:
library("dendextend")#>
#> ---------------------
#> Welcome to dendextend version 1.17.1
#> Type citation('dendextend') for how to cite the package.
#>
#> Type browseVignettes(package = 'dendextend') for the package vignette.
#> The github page is: https://github.com/talgalili/dendextend/
#>
#> Suggestions and bug-reports can be submitted at: https://github.com/talgalili/dendextend/issues
#> You may ask questions at stackoverflow, use the r and dendextend tags:
#> https://stackoverflow.com/questions/tagged/dendextend
#>
#> To suppress this message use: suppressPackageStartupMessages(library(dendextend))
#> ---------------------#>
#> Attaching package: 'dendextend'#> The following object is masked from 'package:stats':
#>
#> cutree
row_dend <- x %>%
dist %>%
hclust %>%
as.dendrogram %>%
set("branches_k_color", k = 3) %>%
set("branches_lwd", c(1, 3)) %>%
ladderize
# rotate_DendSer(ser_weight = dist(x))
col_dend <- x %>%
t %>%
dist %>%
hclust %>%
as.dendrogram %>%
set("branches_k_color", k = 2) %>%
set("branches_lwd", c(1, 2)) %>%
ladderize
# rotate_DendSer(ser_weight = dist(t(x)))
heatmaply(
percentize(x),
Rowv = row_dend,
Colv = col_dend
)Replicating the dendrogram ordering of heatmap.2
The following example shows how to get the same result in heatmaply as with gplots::heatmap.2:
x <- as.matrix(datasets::mtcars)
gplots::heatmap.2(
x,
trace = "none",
col = viridis(100),
key = FALSE
)
With heatmaply, the only difference is the side of the row dendrogram. This is because the ggplotly function from plotly does not (yet) handle axes placed in different locations than the default.
heatmaply(
x,
seriate = "mean"
)We can get a more similar version using:
heatmaply(x,
seriate = "mean",
row_dend_left = TRUE,
plot_method = "plotly"
)Some aspects of heatmaply may not function identically when using plot_method = "plotly" relative to how they function when using plot_method = "ggplot" (the default), however in the majority of cases the output is equivalent. Using this option results in faster heatmaps capable of handling larger matrices.
Adding annotation based on additional factors using RowSideColors
With heatmap.2
# Example for using RowSideColors
x <- as.matrix(datasets::mtcars)
rc <- colorspace::rainbow_hcl(nrow(x))
library("gplots")#>
#> Attaching package: 'gplots'#> The following object is masked from 'package:stats':
#>
#> lowess
library("viridis")
heatmap.2(
x,
trace = "none",
col = viridis(100),
RowSideColors = rc,
key = FALSE
)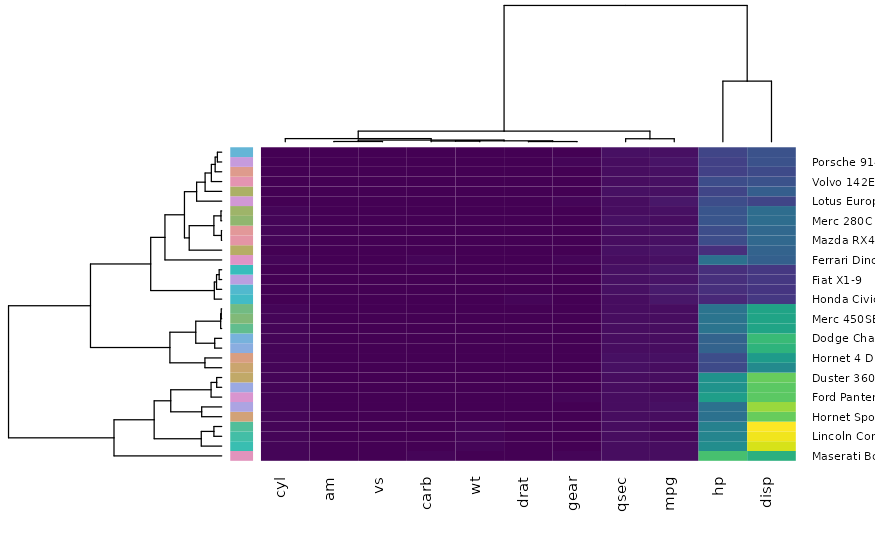
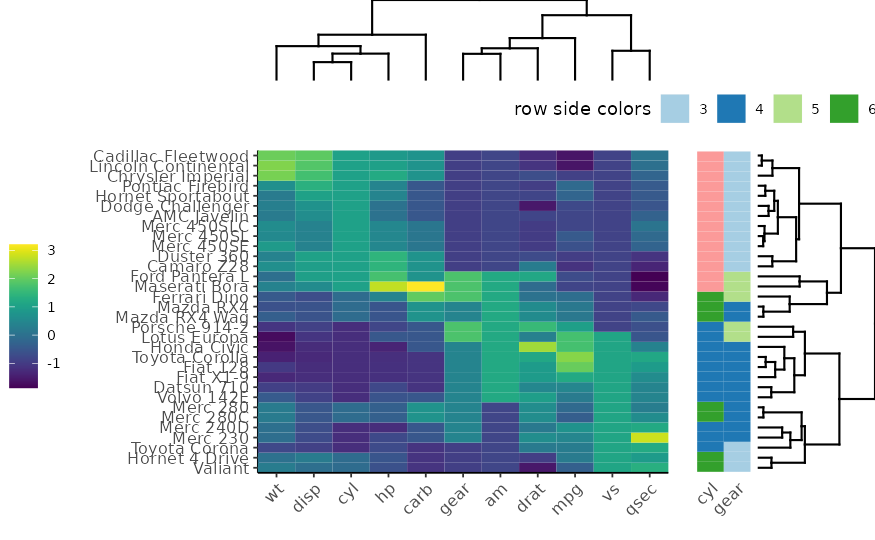
With heatmaply:
heatmaply(
x,
seriate = "mean",
RowSideColors = rc
)A more sophisticated heatmap:
Text annotations
heatmaply includes the cellnote argument, which allows us to display character values overlaid on the heatmap. By default, the colour of the text on each cell is chosen to ensure legibility, with black text shown over light cells and white text shown over dark cells.
heatmaply(
mtcars,
cellnote = mtcars
)Hover text
As hovertext is one of the most useful aspects of interactive heatmaps, heatmaply allows users to append custom hovertext:
ggheatmap
heatmaply also has the option to produce (static) vector graphic equivalents using the excellent egg package. This feature is somewhat experimental, and all feedback and contributions to improve it are highly appreciated.
Saving your heatmaply into a file
You can save an interactive version of your heatmaply into an HTML file using the following code:
dir.create("folder")
heatmaply(mtcars, file = "folder/heatmaply_plot.html")
browseURL("folder/heatmaply_plot.html")Similar code can be used for saving a static file (png/jpeg/pdf)
dir.create("folder")
# Before the first time using this code you may need to first run:
# webshot::install_phantomjs() or to install
# [plotly's orca](https://github.com/plotly/orca) program.
heatmaply(mtcars, file = "folder/heatmaply_plot.png")
browseURL("folder/heatmaply_plot.png")If you only wish to save the file, without plotting it in the console, you can assign the output to a temporary object name:
Sidenotes
We considered using the fastcluster package for clustering, but the time gain was too small compared to the rest of the bottlenecks in the package.
library("microbenchmark")
library("heatmaply")
x <- matrix(1:1000, 500, 2)
microbenchmark(
heatmaply(x, hclustfun = stats::hclust),
heatmaply(x, hclustfun = fastcluster::hclust),
times = 10
)
x <- matrix(1:1000, 1000, 2)
microbenchmark(
stats::hclust(dist(x)),
fastcluster::hclust(dist(x)),
times = 10
)Credit
This package is thanks to the amazing work done by many people in the open source community. Beyond the many people working on the pipeline of R, thanks should go to the plotly team, and especially to Carson Sievert and others working on the R package of plotly. Also, many of the design elements were inspired by the work done on heatmap, heatmap.2 and d3heatmap, so special thanks goes to the R core team, Gregory R. Warnes, and Joe Cheng from RStudio. The dendrogram side of the package is based on the work in dendextend, in which special thanks should go to Andrie de Vries for his original work on the ggdendro package was the first to bring dendrograms to ggplot2 (this later evolved into the richer ggdend objects, as implemented in dendextend). Thanks should also go to Alan O’Callaghan for his many contributions to getting the package to work better with plotly, as well as for Jonathan Sidi for his work on the shinyHeatmply package. Lastely, my thanks goes to Yoav Benjamini for his support and helpful comments on this work.
Contact
You are welcome to:
- submit suggestions and bug-reports at: https://github.com/talgalili/heatmaply/issues
- send a pull request on: https://github.com/talgalili/heatmaply/
- compose a friendly e-mail to: tal.galili@gmail.com
Latest news
You can see the most recent changes to the package in the NEWS.md file
Session info
#> R version 4.3.1 (2023-06-16)
#> Platform: x86_64-pc-linux-gnu (64-bit)
#> Running under: Pop!_OS 22.04 LTS
#>
#> Matrix products: default
#> BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
#> LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.20.so; LAPACK version 3.10.0
#>
#> locale:
#> [1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
#> [3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
#> [5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
#> [7] LC_PAPER=en_US.UTF-8 LC_NAME=C
#> [9] LC_ADDRESS=C LC_TELEPHONE=C
#> [11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
#>
#> time zone: Europe/Dublin
#> tzcode source: system (glibc)
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] gplots_3.1.3 dendextend_1.17.1 knitr_1.43 heatmaply_1.4.3
#> [5] viridis_0.6.3 viridisLite_0.4.2 plotly_4.10.2 ggplot2_3.4.2
#>
#> loaded via a namespace (and not attached):
#> [1] gtable_0.3.3 xfun_0.39 bslib_0.5.0 caTools_1.18.2
#> [5] htmlwidgets_1.6.2 bitops_1.0-7 crosstalk_1.2.0 vctrs_0.6.3
#> [9] tools_4.3.1 generics_0.1.3 tibble_3.2.1 ca_0.71.1
#> [13] fansi_1.0.4 highr_0.10 pkgconfig_2.0.3 KernSmooth_2.23-21
#> [17] data.table_1.14.8 RColorBrewer_1.1-3 desc_1.4.2 assertthat_0.2.1
#> [21] webshot_0.5.5 lifecycle_1.0.3 compiler_4.3.1 farver_2.1.1
#> [25] stringr_1.5.0 egg_0.4.5 textshaping_0.3.6 munsell_0.5.0
#> [29] codetools_0.2-19 seriation_1.4.2 htmltools_0.5.5 sass_0.4.6
#> [33] yaml_2.3.7 lazyeval_0.2.2 pillar_1.9.0 pkgdown_2.0.7
#> [37] jquerylib_0.1.4 tidyr_1.3.0 ellipsis_0.3.2 cachem_1.0.8
#> [41] iterators_1.0.14 TSP_1.2-4 foreach_1.5.2 gtools_3.9.4
#> [45] tidyselect_1.2.0 digest_0.6.32 stringi_1.7.12 dplyr_1.1.2
#> [49] reshape2_1.4.4 purrr_1.0.1 labeling_0.4.2 rprojroot_2.0.3
#> [53] fastmap_1.1.1 grid_4.3.1 colorspace_2.1-0 cli_3.6.1
#> [57] magrittr_2.0.3 utf8_1.2.3 withr_2.5.0 scales_1.2.1
#> [61] registry_0.5-1 rmarkdown_2.23 httr_1.4.6 gridExtra_2.3
#> [65] ragg_1.2.5 memoise_2.0.1 evaluate_0.21 rlang_1.1.1
#> [69] Rcpp_1.0.11 glue_1.6.2 jsonlite_1.8.7 R6_2.5.1
#> [73] plyr_1.8.8 systemfonts_1.0.4 fs_1.6.2